pdf 添加目录
下载到的pdf书籍,只有目录可以跳转没有pdf标签,所以想自动生成pdf标签。
提取目录链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import fitz
def extract_internal_links_with_titles_from_page(pdf_path, page_number):
document = fitz.open(pdf_path)
page = document.load_page(page_number - 1)
links = page.get_links()
internal_links_with_titles = []
for link in links:
if link.get('kind') == 1:
page_dest = link.get('page', -1) + 1
rect = fitz.Rect(link["from"])
text = page.get_text("text", clip=rect)
text = text.strip()
internal_links_with_titles.append((page_dest, text))
return internal_links_with_titles
pdf_path = 'cpp_book.pdf'
page_number = 2
internal_links_with_titles = extract_internal_links_with_titles_from_page(pdf_path, page_number)
for page_dest, title in internal_links_with_titles:
print("{} {}".format(title, page_dest))
|
提取到目录里面的标题和对应的页码后,使用pdfdir https://github.com/chroming/pdfdir 进行自动加标签操作。
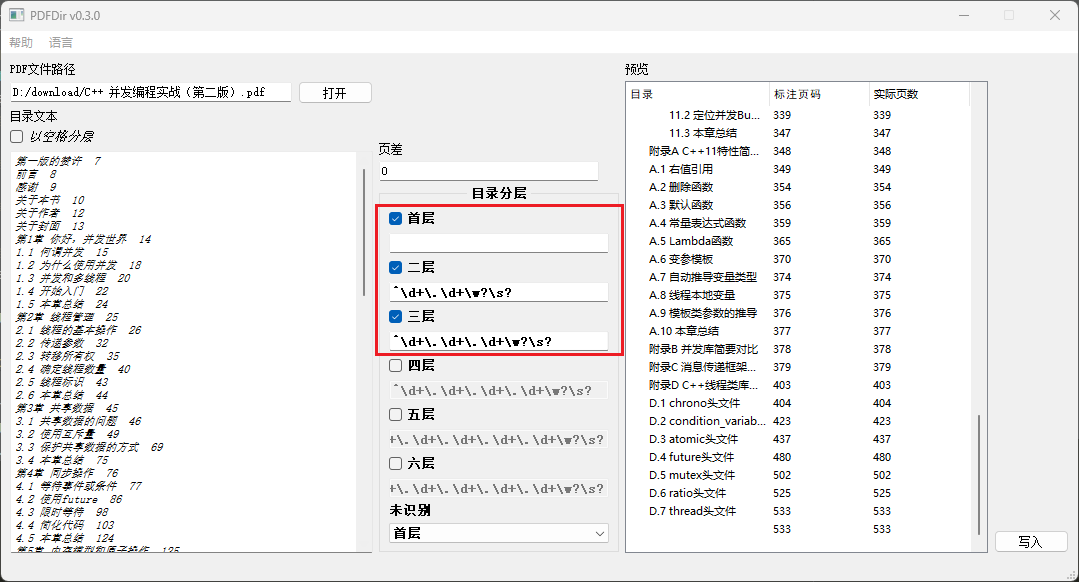
这个里面目录分层信息是正则化匹配:
正则表达式 ^\d+\.\d+\w?\s? 可以匹配以下内容:
^ 表示匹配字符串的开头。\d+ 表示匹配一个或多个数字。\. 表示匹配一个小数点。\d+ 表示匹配一个或多个数字。\w? 表示匹配零个或一个字母、数字或下划线字符。\s? 表示匹配零个或一个空白字符(如空格、制表符等)。
综合起来,这个正则表达式匹配的内容是:以数字开头,紧接着一个小数点,再跟一个或多个数字,之后可能有一个字母或数字或下划线,最后可能有一个空白字符。例如:
这些都是符合该正则表达式的示例。
然后点击写入就ok