
这篇论文主要是说明了序列的长度是影响最后性能的关键因素。一个合理的长序列长度可以产生有意义的收益,而不产生任何额外的下游计算成本。
我理解的论文里面其中一个结论是,如果只是单纯增加序列长度,也不会有性能提升,还得有合适的 mask size (论文里面是选了相邻的四个patch作为一个mask单元)。然后就是,这篇论文的结论都是通过做实验得到的,论文也没有原理和理论解释。
这篇论文主要是提供了一些经验,设patch size小一点,让length长一点,然后用2*2的mask
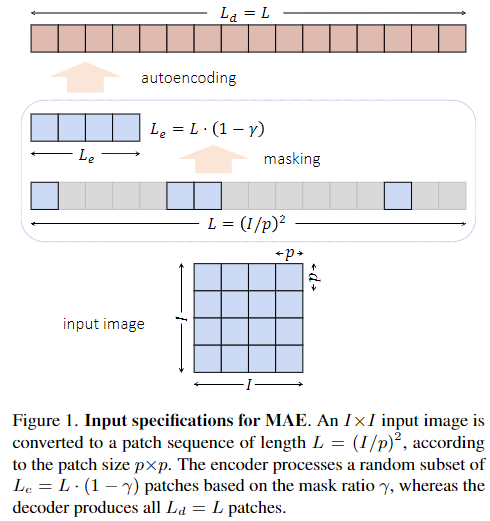
MAE的输入尺寸:
- 一个 I * I 大小的图片,先分成 p * p 的patches
- 最后将二维的patch展开成一维的序列 L = (I /p)^2

mask size
原始的MAE直接输入长序列的话,会存在性能下降和退化。
这里的根本原因是 mask size 和 patch size 大小本质上是两个变量——前者控制任务,而后者与模型相关——但它们在最初的MAE中被设置为一个单独的变量。
论文中认为:
当处理长序列的时候,我们需要有更大的mask size,比如一个 2*2 的mask
(2 * 2 的mask的意思是 4 个相邻的 patch 作为一个屏蔽的单元)
相比于原版的 1*1 的mask size,2 * 2 的可以保留更多的难度。
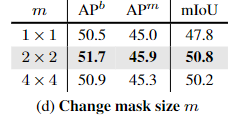
对于长序列的MAE,如果m = 1 * 1,模型大部分使用近处的底层纹理细节进行重建,如果m = 2 * 2 会是一个更有语义的任务。
他的意思是说,m = 1 * 1和m = 2 * 2 他们的序列长度是一样的,但是m = 2 * 2可以保持更好的难度。更有语义的任务。
消融实验
L 序列长度
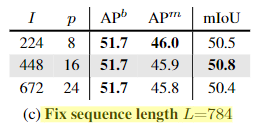
(a)是固定了输入图像的尺寸 I, 此时改变 p (patch size) 会改变L (序列长度)
结论是,L越大效果越好
(b)是固定了 p ,此时改变输入图像的大小,也会改变 L
结论是,L越大效果越好
如果固定 L 序列长度不变,改变 I 和 p, 最后的性能差不多。
mask size
序列长度都是 L = 784 (长序列),
当 m = 2 * 2的时候,效果最好,m = 1 * 1 结果和原始mae的效果差不多。当 m = 4 * 4 时,效果有点下降,可能是因为任务变得有些困难了,并开始产生伤害。
encoder/decoder sequence lengths

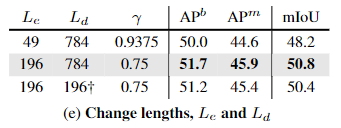
Le 是 encoder 长度,Ld 是decoder长度。r 是遮盖比 mask ratio
第一行的目的是减小 Le 的长度,可以通过调整 mask ratio。这里用的是 0.9375 的比例,我们选择这个比率,因为它具有与MAE baseline 相同的Le,同时匹配默认解码器长度。有趣的是,尽管速度比默认设置快,但结果甚至比基线还差。
这意味着简单地增加掩模比γ不能直接导致更好的表示,与较长的序列相结合的去耦掩模尺寸是更好的解决方案。
也就是 较长的序列长度 + 合适的 mask size
最后一行的目的是减小 Ld 的长度,这里是用了一个 learned 2 * 2 卷积 下采样。将序列从 28 * 28 变成 14 * 14 ,送到解码器。(这样 Ld 长度就变小了)
它不如我们的默认设置(中间行),但是明显好于 减小Le
这些结果表明,较长的Le和较长的Ld都有助于特征质量,其中Le更重要——可能是因为编码器是直接转移到下游任务的编码器。
预训练时间
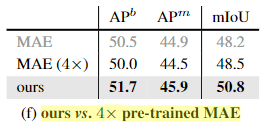
长序列的 MAE也带来了 4 倍的计算量。(L=784) 比 (L=196)
这里,MAE训练了 4 倍的时间 (a 4× long learning schedule is used for original MAE)
但是结果还是不如长序列。
这表明,通过增加序列长度L来花费额外的计算要比将其用于更长的训练计划要好
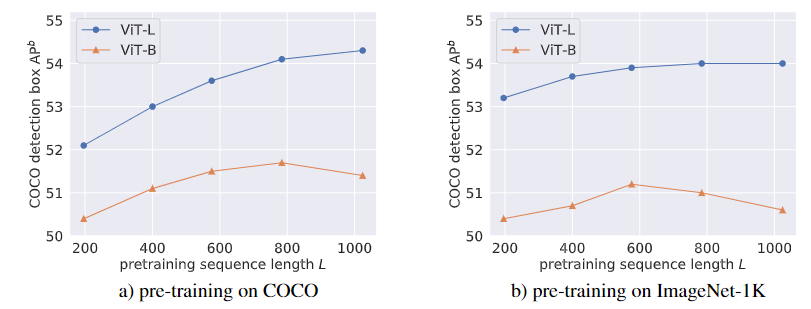
序列长度的缩放趋势
-
左边的图:
对于 larger-sized 的 VIT-L 来说,增大序列长度,可以持续的获得收益。但是 smaller 的 VIT-B 会在到一定序列长度后性能下降。
我们怀疑,VIT-L比VIT-B更好地扩展到更长的预训练序列,因为前者具有更高的建模能力,可以处理大量的输入图像补丁,并学习丰富的特征来表示这些补丁之间的关系(如物体或场景中的部分-整体关系,或视觉组件之间的上下文共发关系)。
-
右边的图:
相比左边的图,可以看出COCO预训练从较长的序列中获益更多:前者提高了2个AP点以上,而后者仅提高了1个AP点。
虽然没有对照研究证明,但我们推测这是因为COCO图像包含更多的对象和场景上下文,因此更适合捕捉这些对象及其交互的较长序列。
最后结论
我们工作的一个潜在限制是,增加序列长度不可避免地增加计算成本,然而,我们相信这种成本可以通过一次训练前运行的各种应用程序的可能性来摊销。而且在这种转移过程中不产生额外成本的情况下,性能的提高是合理的。
虽然我们目前的发现大多是实证的,但我们希望它们能够帮助未来的理论解释,并激发更多这一前沿领域的研究。
英语句子
长期而重要的课题,
Effectively processing data with rich structures is a longstanding and important topic in multiple fields of AI. It is aspirational : e.g., it’s exciting to build systems that can create proper high-resolution images from arbitrary language descriptions
增加精度
… is widely accepted as a most reliable way to boost accuracies.
不断提高的能力
In fact, model developments can also be attributed to their ever-improving ability to capture signals within rich data.
取代
For computer vision, ConvNets supersede fully-connected networks with translation equivariance and pyramidal architectures
… 继承这一特性
Inheriting this property, Vision Transformer (ViT) is quickly gaining popularity in computer vision
问题被…进一步放大
This issue can be further amplified by the ‘curse of dimensionality’ [18] with expanded input sizes.
几乎没有探索过的新的机会,
This presents a fresh opportunity for scaling that’s barely explored in NLP.
源于
Self-supervised learning holds the promise of scalability, which stems from its unsupervised nature that saves labeling costs.